출처 : 위키페디아(http://ko.wikipedia.org/wiki/%EB%A0%88%EB%93%9C-%EB%B8%94%EB%9E%99_%ED%8A%B8%EB%A6%AC)
레드-블랙 트리는 내부적으로 균형을 이룬(self-balancing) 이진 탐색 트리(binary search tree)로써, 대표적으로는 연관 배열(associative array) 등을 구현하는 데 쓰이는 자료구조이다. 최초의 구조는 1972년 루돌프 바이어가 창안했으며, 이를 "대칭형 이진 B-트리"(symmetric binary B-tree)라고 불렀고, 1978년 Leo J. Guibas와 로버트 세지윅이 발표한 논문에서 현재의 이름이 등장하게 되었다. 레드-블랙 트리는 복잡한 자료구조이지만, 실 사용에서 효율적이고, 최악의 경우에도 상당히 우수한 실행 시간을 보인다: 트리에 n개의 원소가 있을 때 O(log n) 의 시간복잡도로 삽입, 삭제, 검색을 할 수 있다.
용어
레드-블랙 트리는 이진 트리의 특수한 형태로써, 컴퓨터 공학 분야에서 숫자 등의 비교 가능한 자료를 정리하는 데 쓰이는 자료구조이다. 이진 트리에서는 각각의 자료가 '노드(node, 분기점)'에 저장이 된다. 이 노드 중 하나는 시작점이 있는데, 시작점은 다른 어떤 노드의 자식(child)노드가 될 수 없다; 이 시작점을 root node, 또는 root라고 부른다.
노드는 자신과 연결되는 최대 두 개의 자식 노드를 가질 수 있다. 각각의 자식 노드도 역시 자신과 연결되는 최대 두 개의 자식 노드를 가질 수 있으며, 이런식으로 계속 연결된다. 그러므로, root node는 자신으로부터 이 트리에 속한 모든 노드에 도달할 수 있는 경로(path)가 있다.
어떤 노드에 자식 노드가 없다면, 그 노드를 leaf node라고 부르는데, 이는 그 노드가 말 그대로 트리의 변방(또는 맨 끝)에 있기 때문이다. 부분트리는 어떤 노드에서부터 시작되는 트리의 일부분이며, 그 자체가 트리이기도 하다. 레드-블랙 트리에서는 leaf node들은 비어있다(null)고 가정한다; 다시 말해서, 자료를 가지고 있지 않는다는 말이다.
레드-블랙 트리를 포함한 이진 탐색 트리는, 모든 노드에 대해 '자신이 가진 자료(data)는 자신보다 오른쪽에 위치한 부분트리가 가지고 있는 모든 data에 대해서 작거나 같고, 자신보다 왼쪽에 위치한 부분트리가 가지고 있는 모든 data에 대해서 크거나 같다' 라는 조건을 만족한다. 이런 특성 때문에 특정 값을 빠르게 찾아 낼 수 있으며, 각 구성원소(elements)간의 효율적인 in-order traversal이 가능하다.
용도와 장점
레드-블랙 트리는 자료의 삽입과 삭제, 검색에서 최악의 경우에도 일정한 실행 시간을 보장한다(worst-case guarantees). 이는 실시간 처리(real-time applications)와 같은 실행시간이 중요한 경우에 유용하게 쓰일 뿐만 아니라, 일정한 실행 시간을 보장하는 또 다른 자료구조를 만드는 데에도 쓸모가 있다. 예를 들면, 각종 기하학 계산에 쓰이는 많은 자료 구조들이 레드-블랙 트리를 기반으로 만들어져 있다.
AVL 트리는 레드-블랙 트리보다 더 엄격하게 균형이 잡혀 있기 때문에, 삽입과 삭제를 할 때 최악의 경우에는 더 많은 회전(rotations)이 필요하다.
레드-블랙 트리는 함수형 프로그래밍(functional programming)에서 특히 유용한데, 함수형 프로그래밍에서 쓰이는 연관 배열(associative array)이나 집합(set)등을 내부적으로 레드-블랙 트리로 구현해 놓은 경우가 많다. 이런 구현에는 삽입, 삭제시 O(log n)만큼의 시간이 필요하다.
레드-블랙 트리는 2-3-4 트리와 등장변환이 가능하다(isometry). 다시 말해서, 모든 2-3-4 트리에는 구성 원소와 그 순서(order)가 같은 레드-블랙 트리가 최소한 하나 이상 존재한다는 말이다. 2-3-4 트리에서의 삽입, 삭제 과정은 레드-블랙 트리에서의 색 전환(color-flipping)과 회전(rotation)과 같은 개념이다. 그러므로 2-3-4 트리는 레드-블랙 트리의 동작 과정(logic)을 이해하는 데 많은 도움을 주며, 이런 이유로 많은 알고리즘 교과서들이 실제로는 잘 쓰이지 않음에도 불구하고 2-3-4 트리를 레드-블랙 트리가 나오기 바로 전에 소개하고 있다.
특성(Properties)

레드-블랙 트리는 각각의 노드가 레드 나 블랙 인 색상 속성을 가지고 있는 이진 탐색 트리이다. 이진 탐색 트리가 가지고 있는 일반적인 조건에 다음과 같은 추가적인 조건을 만족해야 유효한(valid) 레드-블랙 트리가 된다:
- 노드는 레드 혹은 블랙 중의 하나이다. (A node is either red or black.)
- 루트 노드(시작점)은 블랙이다. (The root is black.)
- 모든 leaf node는 블랙이다. (All leaves are black. (The leaves are the NIL children.))
- 레드 노드의 자식노드 양쪽은 언제나 모두 블랙이다. 한편 블랙 노드만이 레드 노드의 부모 노드가 될 수 있다. (Both children of every red node are black. Therefore, a black node is the only possible parent for a red node.)
- 어떤 노드로부터 시작되어 leaf node에 도달하는 모든 경로에는 leaf node를 제외하면 모두 같은 개수의 블랙 노드가 있다.(Every simple path from a node to a descendant leaf contains the same number of black nodes. (Not counting the leaf node.))
위 조건들을 만족하게 되면, 레드-블랙 트리는 가장 중요한 특성을 나타내게 된다: 루트 노드부터 가장 먼 경로까지의 거리가, 가장 가까운 경로까지의 거리의 두 배 보다 항상 작다. 다시 말해서 레드-블랙 트리는 개략적(roughly)으로 균형이 잡혀 있다(balanced). 따라서, 삽입, 삭제, 검색시 최악의 경우(worst-case)에서의 시간복잡도가 트리의 높이(또는 깊이)에 따라 결정되기 때문에 보통의 이진 검색 트리에 비해 효율적이라고 할 수 있다.
왜 이런 특성을 가지는지 설명하기 위해서는, 네 번째 속성에 따라서, 어떤 경로에도 레드 노드가 연이어 나타날 수 없다는 것만 알고 있어도 충분하다. 최단 경로는 모두 블랙 노드로만 구성되어 있다고 했을 때, 최장 경로는 블랙 노드와 레드 노드가 번갈아 나오는 것이 될 것이다. 다섯 번째 속성에 따라서, 모든 경로에서 블랙 노드의 수가 같다고 했기 때문에 존재하는 모든 경로에 대해 최장 경로의 거리는 최단 경로의 거리의 두배 이상이 될 수 없다.
트리 구조를 나타낼 때, 어떤 노드는 자식(child)를 하나만 가질 수도 있고, leaf node는 데이터를 담고 있을 수 있다. 레드-블랙 트리도 이와 같은 방법으로 나타내 볼 수도 있지만, 그런 표현 방식으로는 레드-블랙 트리의 특성이 변하게 되고, 알고리즘과 상충되게 나타날 수 있다. 그래서, 이 문서에서는 "nil leaves" 나 "null leaves"를 사용하고 있는데, 이 "null leaf"는 위의 그림에서와 같이 자료를 가지고 있지 않으며, 트리의 끝을 나타내는 데만 쓰인다. 트리 구조를 그림으로 표현할 때, 종종 이 "null leaf"를 생략하고 그리는 경우가 많은데, 그렇게 되면 그림상으로는 레드-블랙 트리의 특성을 만족하지 못하는 것처럼 보일 수 있으나 실제로는 그렇지 않다. 이렇게 함으로써, 모든 노드들은 설령 하나 또는 두개의 자식이 "null leaf" 일지라도, 두개의 자식(children)을 가지게 된다.
간혹 레드-블랙 트리를 노드가 아닌 붉은색 또는 검은색 선분(edge)으로 설명하기도 하는데, 실제로는 같은 이야기이다. 어떤 노드의 색은 노드와 그 부모를 연결하는 선분의 색에 대응되기 때문인데, 차이점이 있다면 레드-블랙 트리의 두 번째 속성에서 언급된 root node가 선분으로 설명할 경우 존재하지 않는다는 점이다.
동작
레드-블랙 트리의 읽기 전용(read-only) 동작(검색 등)은 이진 탐색 트리의 읽기 전용 동작의 구현을 변경하지 않아도 되는데, 이는 레드-블랙 트리가 이진 탐색 트리의 특수한 한 형태이기 때문이다. 그러나 삽입(insertion)과 삭제(removal)의 경우 이진 탐색 트리의 구현에 따른 동작만으로는 레드-블랙 트리의 특성을 만족하지 못하게 된다. 레드-블랙 트리의 특성을 다시 만족하게 만들기 위해서는 O(log n) 또는 amortized O(1)번의 색 변환과(실제로는 매우 빨리 이루어진다) 최대 3회의 트리 회전(tree rotation)이 필요하다(삽입의 경우 2회). 삽입과 삭제는 복잡한 동작이지만, 그 복잡도는 여전히 O(log n)이다.
[편집] 삽입(Insertion)
레드-블랙 트리의 삽입은 단순 이진 탐색 트리에서 하는 것과 같이 노드를 삽입하고, 색을 붉은색으로 정하는 것으로 시작한다. 그 다음 단계는, 그 주위 노드의 색에 따라 달라진다. 여기서 '삼촌 노드' 라는 것을 도입할텐데, 이는 같은 높이에 있는 옆 노드(다시 말해, 사촌)의 부모 노드(삼촌)를 뜻한다. 여기서 레드-블랙 트리의 특성이 추가된다 :
- 특성 3 (null node를 포함한 모든 leaf node는 검정색이다)는 언제나 변하지 않는다.
- 특성 4 (적색 노드의 모든(두) 자식은 검정색이다)는 적색 노드의 추가, 검정색 노드의 적색 노드로의 전환, 회전(rotation)에만 의해서 제대로 지켜지지 않는 상황이 된다.
- 특성 5 (어떤 노드로부터 시작되어 leaf node에 도달하는 모든 경로에는 모두 같은 개수의 블랙 노드가 있다)는 검정색 노드의 추가, 적색 노드의 검정색 노드로의 전환, 회전(rotation)에만 의해서 제대로 지켜지지 않는 상황이 된다.
- 주의: 삽입하는 원소를 N, N의 부모 노드를 P, P의 부모를 G, 마지막으로 N의 삼촌 노드를 U로 나타내기로 한다. 설명 도중 각 노드의 역할과 이름이 바뀌지만, 각각의 경우 노드에 붙은 이름(label)은 각 경우에 최초의 상황에서의 이름을 나타낸다. 도표에서 보여지는 색상은 각각의 경우에 예상되는 색이거나, 예상된 색에 의해 유추된 색이다.
또한 각각의 경우를 C 으로 만든 예제를 통해 보여줄 것이다. 삼촌 노드와 할아버지 노드는 다음과 같은 함수(function)에 의해 나타낼 수 있다:
node grandparent(node n) {
return n->parent->parent;
}
node uncle(node n) {
if (n->parent == grandparent(n)->left)
return grandparent(n)->right;
else
return grandparent(n)->left;
}
첫 번째 경우: N 이라고 하는 새로운 노드가 트리의 시작(root)에 위치한다. 이 경우, 레드-블랙 트리의 첫 번째 속성(트리의 시작은 검정색이다)을 만족하기 위해서, N을 검정색으로 표시한다. 이 경우, 시작점으로부터 뻗어나가는 모든 경로에 검정색 노드를 하나 추가한 셈이 되기 때문에 레드-블랙 트리의 다섯 번째 속성(한 노드에서부터 뻗어나가는 모든 경로에 대해 검정색 노드의 수는 같다)은 여전히 유효하다.
void insert_case1(node n) {
if (n->parent == NULL)
n->color = BLACK;
else
insert_case2(n);
}
두 번째 경우: 새로운 노드의 부모 노드 P가 검정색이므로, 레드-블랙 트리의 네 번째 속성(붉은색 노드의 모든 자식 노드는 검정색이다)은 유효하다. 그러므로 두 번째 경우에도 이 트리는 적절한 레드-블랙 트리이다. 레드-블랙 트리의 다섯 번째 속성(한 노드에서부터 뻗어나가는 모든 경로에 대해 검정색 노드의 수는 같다)도 별 문제가 없는데, 이는 새로운 노드 N은 두개의 검정색 노드를 leaf node로 가지고 있기 때문이다. 비록 N이 붉은색 노드라고 해도 N이 들어간 자리에 원래 위치했던 노드의 색이 검정색이었으므로, N의 자식 노드에게서 시작되는 경로들은 모두 같은 수의 검정색 노드를 가지게 되고, 결과적으로 다섯 번째 속성은 유지되게 된다.
void insert_case2(node n) {
if (n->parent->color == BLACK)
return; /* Tree is still valid */
else
insert_case3(n);
}
- 주의: 위의 경우, N은 할아버지 노드 G를 가지고 있다고 가정해도 되는데, N의 부모 노드가 붉은색이라면 그 부모 노드가 root node가 될 수 없고, 붉은색 노드의 부모 노드는 검정색 노드 밖에 될 수 없기 때문이다.
또한 N은 삼촌 노드가 있다고 가정할 수 있는데, 위의 네 번째, 다섯 번째 노드에서는 leaf node에 해당한다.

|
void insert_case3(node n) {
if (uncle(n) != NULL && uncle(n)->color == RED) {
n->parent->color = BLACK;
uncle(n)->color = BLACK;
grandparent(n)->color = RED;
insert_case1(grandparent(n));
}
else
insert_case4(n);
}
- 주의: 이 후의 단계에서는 부모 노드 P가 할아버지 노드 G의 왼쪽 자식이라고 가정하고 진행하도록 한다. 만약 P가 G의 오른쪽 자식이라고 했을 때는 네 번째, 다섯 번째 경우에서 왼쪽과 오른쪽을 바꿔서 진행하면 된다. 소스 코드에서는 이를 이미 고려해서 작성되었다.
 네 번째 경우: 부모 노드 P가 붉은색인데, 삼촌 노드 U는 검정색이다; 또한 새로운 노드 N은 P의 오른쪽 자식 노드이며, P는 할아버지 노드 G의 왼쪽 자식 노드이다. 이 경우, N과 P의 역할을 변경하기 위해서 왼쪽 회전을 하게 된다; 그 후, 부모 노드였던 P를 다섯 번째 경우에서 처리하게 되는데, 이는 레드-블랙 트리의 네 번째 속성(붉은색 노드의 모든 자식은 검정색 노드이다)을 아직 만족하지 않기 때문이다. 회전 작업은 몇몇 경로들("1" 이라는 이름이 붙어 있는 부분 트리(sub-tree))이 이전에는 지나지 않았던 노드를 지나게 하는데, 그럼에도 양쪽 노드가 모두 붉은색이므로, 레드-블랙 트리의 다섯 번째 속성(한 노드에서부터 뻗어나가는 모든 경로에 대해 검정색 노드의 수는 같다)을 위반하지 않는다. |
void insert_case4(node n) {
if (n == n->parent->right && n->parent == grandparent(n)->left) {
rotate_left(n->parent);
n = n->left;
} else if (n == n->parent->left && n->parent == grandparent(n)->right) {
rotate_right(n->parent);
n = n->right;
}
insert_case5(n);
}
 다섯 번째 경우: 부모 노드 P는 붉은색이지만 삼촌 노드 U는 검정색이고, 새로운 노드 N이 P의 왼쪽 자식 노드이고, P가 할아버지 노드 G의 왼쪽 자식 노드인 상황에서는 G에 대해 오른쪽 회전을 한다. 회전의 결과 이전의 부모 노드였던 P는 새로운 노드 N과 할아버지 노드 G를 자식 노드로 가지게 된다. G가 이전에 검정색이었고, P는 붉은색일 수밖에 없기 때문에, P와 G의 색을 반대로 바꾸면 레드-블랙 트리의 네 번째 속성(붉은색 노드의 두 자식 노드는 검정색 노드이다)을 만족하게 된다. 레드-블랙 트리의 다섯 번째 속성(한 노드에서부터 뻗어나가는 모든 경로에 대해 검정색 노드의 수는 같다)은 계속 유지되는데, 이는 이전에 P를 포함하는 경로는 모두 G를 지나게 되고, 바뀐 후 G를 포함하는 경로는 모두 P를 지나게 되기 때문이다. 바뀌기 전에는 G가, 바뀐 후에는 P가 P, G, N중 유일한 검정색 노드이다. |
void insert_case5(node n) {
n->parent->color = BLACK;
grandparent(n)->color = RED;
if (n == n->parent->left && n->parent == grandparent(n)->left) {
rotate_right(grandparent(n));
} else {
/* Here, n == n->parent->right && n->parent == grandparent(n)->right */
rotate_left(grandparent(n));
}
}
삽입 동작은 치환 작업인데, 이는 모든 호출(call)이 tail recursion이기 때문이다.
'자료구조' 카테고리의 다른 글
| [Sorting] Sort algorithm 설명 동영상(Insertion, shell, bubble, selection, Quick, Shaker..) (0) | 2011.07.16 |
|---|---|
| Skip list _ wikipedia (0) | 2011.03.09 |



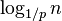 lists.
lists. which is
which is  when p is a constant. By choosing different values of p, it is possible to trade search costs against storage costs.
when p is a constant. By choosing different values of p, it is possible to trade search costs against storage costs.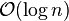 search time. (Choose the level of the i'th finite node to be 1 plus the number of times we can repeatedly divide i by 2 before it becomes odd. Also, i=0 for the negative infinity header as we have the usual special case of choosing the highest possible level for negative and/or positive infinite nodes.) However this also allows someone to know where all of the higher-than-level 1 nodes are and delete them.
search time. (Choose the level of the i'th finite node to be 1 plus the number of times we can repeatedly divide i by 2 before it becomes odd. Also, i=0 for the negative infinity header as we have the usual special case of choosing the highest possible level for negative and/or positive infinite nodes.) However this also allows someone to know where all of the higher-than-level 1 nodes are and delete them.
